
Flexibles Kennzahlreporting für die Nearshore- Servicedomäne
Wie bei vielen unserer Kunden, dreht sich auch unser jüngstes Projekt um mehr als "nur" einen Use Case. Zum Einen soll ein Kennzahlsystem geschaffen werden mit dessen Hilfe der Fachbereich einer Service-Domäne in Zukunft möglichst unabhängig von der IT sein Kennzahl-Reporting entwickeln kann. Zum Anderen geht es aber auch darum zu klären, ob die aktuell eingesetzte Datenplattform für diese und zukünftige Anforderungen optimal geeignet ist.
Projektvorgehen
Wir empfehlen in allen Projekten mit fachlichem Bezug eine Vorabanalyse des Status Quo. Um eine Situation zu verbessern, an der mehrere Parteien beteiligt sind, muss man zunächst ein Verständnis für alle unterschiedlichen Perspektiven entwickeln. Das Ziel ist eine gemeinsame fachliche Sicht auf das Problem, Hintergründe und Zusammenhänge herzustellen und nicht über Technik und Software zu philosophieren. Erst später sollen aus dem oder den ermittelten Use-Cases (die mit dem größten fachlichen Nutzen) die Anforderungen in Bezug auf den Entwurf einer geeigneten Datenarchitektur und -plattform abgeleitet werden. So ist gewährleistet, dass immer der tatsächliche Business-Nutzen im Vordergrund aller Entscheidungen und Investitionen steht.
Status Quo
Die anfängliche Situation bei unserem Kunden sieht so schlecht aus, dass wir nicht einmal den Einladungsprozess wie geplant bewältigen können: Einige wichtige Stakeholder haben ausrichten lassen, dass sie nicht am geplanten Workshop teilnehmen werden. So blieb uns nichts anderes übrig, als den Termin mit den übrigen Teilnehmern so gut wie möglich durchzuführen. In unserem ersten Workshop gelang es uns dennoch, die Abläufe in der Servicedomäne zu skizzieren und die für die Teilnehmer wesentlichen Ereignisse zu identifizieren. Dabei sind einige Engpässe aufgefallen. Das wesentliche Problem besteht auf Grund einer bisher vernachlässigten Abhängigkeit zu einem anderen Fachbereich. Um diese Aufzulösen sollen in einem ersten Schritt zentrale Kennzahlen um entsprechende Steuerungsgrößen erweitert werden.
In der Serviceeinheit selbst ist ein Analyst für die Pflege der Kennzahlen der Services seines Teams verantwortlich. In seinem Bereich kennt er sich sehr gut aus und kann dynamisch mit dem vorhandenen Frontend-Werkzeug Dashboards und Kennzahlberichte entwickeln. Auch ist er in der Lage wirklich hervorragendes SQL für komplexere Abfragen zu erstellen und auch mit einfachen statistischen Funktionen kommt er gut klar. Bisher wurden allerdings alle KPIs von den Daten abgeleitet, die sein Team selbst produziert. Nun müssen zusätzliche Informationen von einem anderen Fachbereich in die Steuerungsgrößen der Service-Domäne mit einfließen. Stand heute gibt es keine Möglichkeit auf diese Daten aus der Service-Domäne heraus zuzugreifen.
Die Suche nach dem Data Owner
Nach einiger Recherche wurden wir an ein Team verwiesen, das für diese Daten zuständig sein soll und nahmen Kontakt auf. Eine gute Woche verging, bis wir einen Zeitslot für ein gemeinsames Meeting gefunden hatten. Leider stellte sich heraus, dass das Team zwar grundsätzlich für den Service verantwortlich ist, aber keinen Zugriff auf die Daten hat. Im wöchentlichen Jour Fix mit dem zentralen BI-Team erfuhren wir von einem Data Lake Team, welches über die betreffenden Daten in Amazon S3 verfügen sollte. Eine weitere Woche verging bis ich die Möglichkeit zu einem Austausch über unsere genauen Anforderungen ergab. Das Treffen verlief positiv, so dass wir einen Folgetermin verabredeten, um uns gemeinsam direkt am System anzuschauen, welche Informationen im Data Lake zur Verfügung stehen und aus welcher Datenquellen diese Informationen stammen.
Nur ein paar Tage später fand der gemeinsame Termin statt. Tatsächlich war es für das Data Lake Team kein Problem die Daten in einem S3 Bucket zu lokalisieren. Zu unserer Überraschung stellte sich jedoch heraus, dass die Daten von einem SAP System geliefert werden, welches der Domäne gehört die wir zuerst kontaktiert hatten. Die eigentliche Quelle war eine sehr alte Planungsanwendung, die die Daten mittels Retraktion zurück an das ERP-System übertrug und von dort aus, zusammen mit anderen Daten an den AWS Data Lake übertragen wurde. Dieses Zusammenhangs war sich im Fachbereich niemand mehr bewusst. Die Anwendung wurde zwar über eine moderne Frontendoberfläche noch regelmäßig genutzt, über die zuverlässig arbeitenden Mechanismen im Backendsystem hatte aber schon lange niemand mehr nachgedacht.
Da es sich nicht um personenbezogene Daten handelte und auch sonst keine besonderen Datenschutzanforderungen beachtet werden mussten kamen wir mit dem Data Lake Team überein, dass die Daten auf Grund der Wichtigkeit für die Serviceeinheit im ersten Schritt von dort aus "auf dem kurzen Dienstweg" dieser zur Verfügung gestellt werden. Schließlich war unser Projekt nun schon um ein paar Woche verzögert und wir waren sehr dankbar für diese unbürokratische Unterstützung.
Als der Business Analyst der Servicedomäne nach einigen kleineren Anpassungen am Datenformat zur reibungslosen Überleitung an das Zielsystem dann Zugriff auf die Daten hatte, konnte er die erweiterte KPI-Berichterstattung mühelos einrichten und nach einiger Zeit sogar um eine Prognosefunktion erweitern. So konnte ein wesentlicher Engpass in der Steuerung der Servicedomäne beseitigt werden. Zumindest vorerst.
Totalausfall dank Optimierung
Nach einigen Monaten des reibungslosen Betriebs kam es plötzlich zu starken Abweichungen. Nicht in jedem Fall, sondern vor allem im wichtigsten Servicesegment. Hier kam es zu so großen Abweichungen, dass diese Werte außerhalb plausibler Grenzen anzeigten. Bis eine Überprüfung der Datenflüsse mit Hilfe der zentralen IT durchgeführt werden konnte, vergingen mehrere Wochen. Zu viele Anforderungen und Anfragen anderer Fachbereiche wurden höher priorisiert als die Probleme in unserem Kennzahlsystem. Einige Stakeholder fingen dadurch bereits an, nicht nur an der einen Kennzahl, sondern an der Nützlichkeit des gesamten Ansatzes und der Advanced Analytics Methodik zu zweifeln. Sie stellten die berechtigte Frage, wie zuverlässig das System wohl an anderer Stelle sei, wenn Abweichungen weniger schwerwiegend und damit weniger auffällig sind?
Schlussendlich stellte sich heraus, dass alle Verbindungen technisch völlig intakt waren. Auch alle Datenquellen lieferten regelmäßig und zuverlässig Daten. Damit konnte die Ursache also nur in den Daten selbst zu finden sein... Im Rahmen weiterer intensiver Nachforschungen konnte schließlich festgestellt werden, dass sich das Format eines Attributs geändert hatte, ohne dass dies bei Datentransfer zu einem syntaktischen Fehler geführt hätte. Allerdings wurden so besonders positive Werte durch einen Fehler in der Vorzeichenberechnung zu negativen Werten und so kamen in der Folge im Zielsystem völlig unbrauchbare Summen an. Auf Grund von Überlastung war man noch nicht dazu gekommen über die Änderungen zu informieren. Allerdings hatte man eine besondere Dringlichkeit hier auch nicht gesehen.
Als wir die Ursache im folgenden Meeting thematisierten entstand so etwas wie Wut auf das datenproduzierende Team. Sie waren für all die zusätzliche Arbeit verantwortlich. Ja, wir konnten uns sogar selbst dabei ertappen, wie wir über "das andere Team, das immer alles falsch macht" gelästert haben. Mit dieser Einstellung wandten wir uns an die verantwortliche Domäne. Dort war man sehr froh über den Termin. Zwischenzeitlich hatte sich das Team viele Gedanken um Daten gemacht. Wir wären deshalb sicher froh zu erfahren, dass man dort nach der Entdeckung der Abhängigkeit zwischen Retraktion und Datenbereitstellung an den Data Lake eine Datenqualitätsmaßnahme durchgeführt hatte. Diverse Eigenschaften an den bereitgestellten Daten wurden optimiert. Dem Team war aber natürlich die Abhängigkeit dieser Felder für die Berechnungslogik in unserem Kennzahlsystem nicht klar. Man hatte in bester Absicht gehandelt und aus eigener Perspektive die Daten ganz wesentlich verbessert....
Wir sitzen alle im selben Boot
An keiner Stelle des - zugegebenermaßen etwas konstruierten, aber sicher nicht aus der Luft gegriffenen Beispiels - war ein technisches Problem die Ursache, oder der Engpass für die Realisierung des Szenarios. Um es deshalb ganz klar zu sagen: Ein Data Lake kann helfen, Engpässe zu beseitigen. Die Lösung ist er aber sicher nicht. Vielmehr sind, wie in unserem Beispiel, unklare (Daten-) Zuständigkeiten, fehlendes Bewusstsein und mangelnde Übernahme von Verantwortung die eigentlichen Hürden. Die zunehmende Bedeutung von Daten ist dabei vielen durchaus bewußt. Doch die Wertschätzung für Daten die durch eigene Tätigkeit entstehen bleibt eher gering. Im Zentrum der Überlegungen der meisten Personen stehen transaktionale Anwendungsfälle und Abhängigkeiten. Das haben wir über viele Jahrzehnte so gelernt. Alle übrigen Informationen werden oft als reines Nebenprodukt angesehen. Etwas, dass bei der "eigentlichen Arbeit" anfällt, für die eigene Tätigkeiten aber wenig Bedeutung hat. Gar nicht so selten haben die Menschen in den Fachbereichen nicht einmal Zugriff auf die Daten, die sie selbst produzieren. In der Folge darf es niemanden verwundern, dass niemand bereit ist für die Daten die Verantwortung zu übernehmen.
Fehlende (Daten-) Transparenz, zentrale (Personal-) Engpässe und eigene Überlastung. Letztlich geschieht nur sehr selten etwas in wirklich böser Absicht. Im Fallbeispiel wollte der Daten liefernde Fachbereich sogar helfen, in dem er die Datenqualität proaktiv verbessern wollte. Versetzt man sich in die Perspektive des anderen stellt man schnell fest, dass alle mit den gleichen Problemen kämpfen.
Ein Ausweg aus dem Flaschenhals?
Probleme zu erkennen ist das eine Sie zu lösen etwas anderes. Noch immer herrscht in Unternehmen ein starker Trend zur Zentralisierung von Unternehmensdaten: Alle Informationen sollen in einer zentralen monolithischen Datenbasis konsolidiert werden, um eine einzige Quelle der Wahrheit, eine "Single source of truth" bereit zu stellen. Viele Unternehmen halten deshalb den Data Lake für den ausgemachten Nachfolger des Data Warehouse. Doch es sind nicht Limitierungen der Technik, sondern eben jeder zentralistische Ansatz der zur zuvor skizzierten Situation geführt hat. Wieso sollte sich daran, bei unverändertem Vorgehen unter Verwendung einer anderen Technologie irgendetwas ändern? Um zu einem Unternehmen zu werden, welches Daten nutzt um Freiräume zu gewinnen, Geschäftsmodelle zu verbessern und Innovationen zu ermöglichen braucht es einen grundlegenden Haltungswechsel.
Konsequenzen für die Datenarchitektur
Im Bereich der operativen Daten begannen die Architekten schon vor einiger Zeit sich vom Paradigma der Zentralisierung zu entfernen. Seit dem Aufkommen von NoSQL und Microservices ist es mehr oder weniger zum Standard geworden, dass jeder Service seinen eigenen Datenspeicher unterhält. Die Anwendung dieses Prinzips auf Analysedaten verfolgt das Data Mesh.
Doch Data Mesh geht deutlich weiter. Es handelt sich also nicht einfach um eine andere oder neue Softwarearchitektur. Das Data Mesh ist vielmehr ein dezentraler soziotechnischer Ansatz für die gemeinsame Nutzung, den Zugriff und die Verwaltung von Daten in komplexen und groß angelegten Umgebungen. Sowohl innerhalb einer Organisation oder auch organisationsübergreifend. Die logische Architektur und das Betriebsmodell des Data Mesh lassen sich in vier einfachen Prinzipien zusammenfassen.

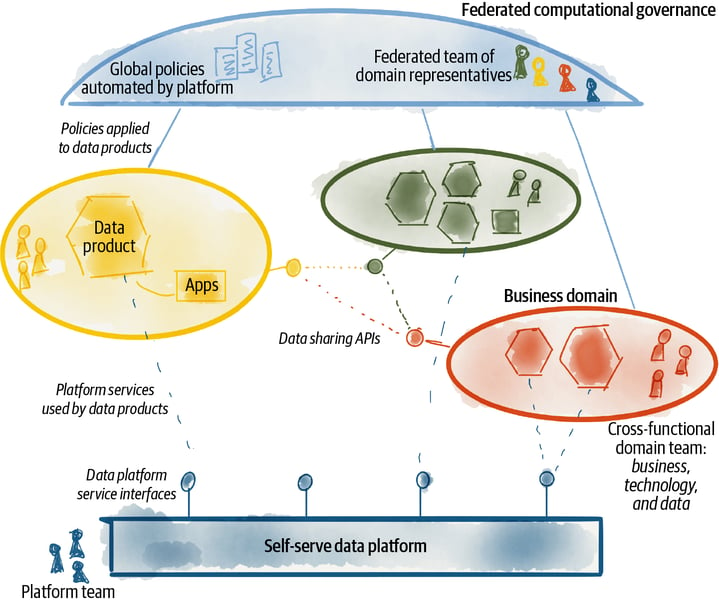
Das Prinzip des Domäneneigentums
Analytische Daten werden logisch und basierend auf der Geschäftsdomäne, die sie repräsentieren über den kompletten Lebenszyklus dezentral verwaltet. "Eigentum" und Verantwortung gehen also auf die Geschäftsbereiche über, die den Daten am nächsten stehen. Sie sind entweder selbst Produzent der Daten oder ihr Hauptkonsument.
Das Prinzip der Self-Service-Datenplattform
Im Mittelpunkt dieser neuen Generation von Self-Serve-Datenplattformdiensten steht die Beseitigung von Reibungsverlusten bei der gemeinsamen Nutzung von Daten. Zu diesem Zweck verwalten die Plattformdienste ein zuverlässiges Netz von miteinander verbundenen Datenprodukten über deren kompletten Lebenszyklus. Datennutzern fällt es dadurch leicht Datenprodukte zu entdecken und darauf zuzugreifen. Datenanbietern erleichtern sie die Erstellung, Bereitstellung und Pflege ihrer Datenprodukte. Daneben stehen Mehrwertdienste auf Mesh-Ebene, wie z. B. entstehende Wissensgraphen oder die Abstammung der Daten innerhalb des Meshs zur Verfügung.
Das Prinzip von Daten als Produkt
Bereichsorientierte Daten werden wie ein Produkt entwickelt und gemanaged. Das bedeutet, sie haben insbesondere auch immer einen direkten Kundenbezug. Kunden sind alle Nutzer dieses Datenprodukts wie bspw. Datenanalysten, Datenwissenschaftlern usw. Jedes Datenprodukt ist autonom und sein Lebenszyklus und Modell werden unabhängig von anderen Datenprodukten verwaltet.
Mit Daten als Produkt wird eine neue Einheit der logischen Architektur eingeführt, die Datenquantum genannt wird. Dieses beinhaltet alle strukturellen Komponenten, die für die gemeinsame Nutzung eines Datenprodukts neben den eigentlichen Daten erforderlich sind: Metadaten, Code, Richtlinien und Abhängigkeiten in Bezug auf die Infrastruktur. Ein solches Datenquantum ist logisch gekapselt und wird autonom gesteuert.
Das Prinzip der föderalen Governance in der Datenverarbeitung
Das im Data Mesh angewandte Data-Governance-Betriebsmodell basiert auf föderalen Entscheidungs- und Verantwortungsstrukturen. Das verantwortliche Team setzt sich aus Vertretern des Fachbereichs, der Datenplattform und Fachexperten (Recht, Compliance, Sicherheit usw.) zusammen. Das Betriebsmodell schafft eine Anreiz- und Verantwortungsstruktur, die ein Gleichgewicht zwischen der Autonomie und Agilität der Bereiche und der globalen Interoperabilität des Netzes schafft. Die Umsetzung der Governance stützt sich in hohem Maße auf die Kodifizierung und Automatisierung der Richtlinien über die Plattformdienste auf granularer Ebene für jedes einzelne Datenprodukt .
Vom einfachen Use Case zum datengesteuerten Unternehmen
Wir wollen Data Mesh hier nicht als Allheilmittel für all ihre Probleme anpreisen. Wir wollen anhand dieses Beispiels zeigen, warum und wieso Technik und organisatorische Gegebenheiten in Einklang gebracht werden müssen, um am Ende erfolgreich zu sein. Data Mesh kann in Ihrem Unternehmen eine Lösung sein, muss es aber nicht. Wesentlich ist, dass Sie Projekte und Initiativen viel ganzheitlicher angehen, als Sie das möglicherweise bisher getan haben. Dann bedient jeder Use Case und jedes Projekt nicht nur einen Business Case, sondern bietet immer auch eine Chance das Unternehmen als datengesteuertes Unternehmen weiter zu entwickeln.
Können wir etwas für Sie tun?
Kennen Sie schon unser Whitepaper Transformation zum datengesteuerten Unternehmen? Dort können Sie mehr über Erfolgsfaktoren und unseren Beratungsansatz erfahren.
Haben Sie Lust uns näher kennen zu lernen? Nehmen Sie doch einfach unverbindlich Kontakt auf, oder vereinbaren Sie direkt über unsere Homepage einen Kennenlerntermin mit uns.
Ähnliche Beiträge:


Erfahren Sie mehr über die 6 häufigsten Irrtümer beim Aufbau eines Data Lakes. Unser Artikel beleuchtet die Organisation unstrukturierter Daten, die Bedeutung von Metadaten und die kontinuierliche Entwicklung der Datenplattform. Entdecken Sie klare Standards, Automatisierung und Teamkommunikation für einen erfolgreichen Data Lake. Erfahren Sie mehr in unserem E-Book 'Lakehouse Automation'.

