
Mithilfe nativer HANA-Programmierung und verschiedener Frontends lassen sich komplexe Data Science-Anwendungen realisieren, ohne auf externe Anwendungen zurückgreifen zu müssen. Im Gegensatz dazu werden fortgeschrittene Datenanalysen im Data Science-Umfeld heutzutage vor allem in der Programmiersprache Python ausgeführt, da sie einen riesigen Fundus an einschlägigen Bibliotheken bietet.
Die Lösung: Code Pushdown
In einem typischen Anwendungsfall liegen die Daten in einem SAP-System vor und sollen mit Machine Learning-Techniken analysiert werden. Hierbei ist die Vorgehensweise in Python nicht ideal. Daten müssen langsam vom Quellsystem auf einen Python-Anwendungsserver übertragen werden und dort zusätzlich vorgehalten werden - gerade bei großen Datenmengen oder zeitkritischen Anforderungen ein entscheidender Nachteil.
Idealerweise sollte daher die Analyse mit der Flexibilität und Erweiterbarkeit von Python, aber möglichst auf dem Quellsystem selbst durchgeführt werden. Die Lösung ist Code Pushdown: der Code muss zu den Daten, statt die Daten zum Code. Die Bibliothek hana_ml, kurz für “Python Machine Learning Client for SAP HANA“, ermöglicht genau dieses Prinzip in HANA. Die im Blogbeitrag "Data Science in HANA" bereits vorgestellte PAL lässt sich damit aus Python heraus aufrufen, wobei die Ausführung der Funktionen in HANA selbst erfolgt. Zusätzlich bietet hana_ml einige hilfreiche Erweiterungen.
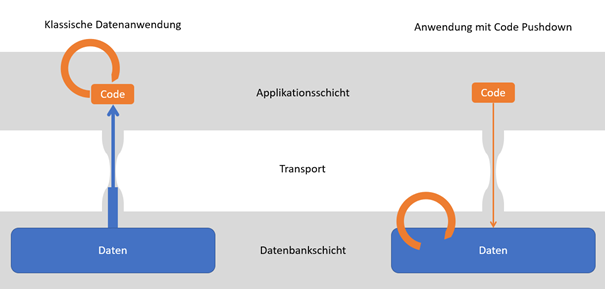
Abbildung: Per Code Pushdown kommt der Code zu den Daten anstatt die Daten zum Code. Die Übertragung großer Datenmengen aus der Datenbank zum Applikationsserver stellt einen Flaschenhals dar. Bleiben stattdessen die Daten an Ort und Stelle, lassen sich Geschwindigkeit und Effizienz einer datenbasierten Anwendung steigern. Bei der Datenanalyse durch Machine Learning kommt dies besonders zu Tragen. Eigene Darstellung
Machine Learning mit Python, aber in HANA
Bleiben wir bei der Vorhersage von Verkaufszahlen eines Spielwarengeschäfts. Statt der limitierten nativen HANA-Programmierung oder der Bedienung über ein angepasstes Frontend soll die Analyse nun in einem Jupyter-Notebook erfolgen, wie es typischerweise von Data Scientists zur explorativen Analyse verwendet wird.
Ein wichtiger Bestandteil jedes Data Science-Projekts ist die Vorbereitung der Daten. Neben dem Vertrautmachen mit den Daten und ihrer Struktur, gehört dazu auch die Bereinigung, Selektion und Anreicherung mit weiteren Informationen. Oft sind in den vorhandenen Tabellen viel mehr Daten/Spalten vorhanden, als für das konkrete Projekt benötigt werden und andererseits müssen weitere Tabellen bspw. mit Joins angebunden werden. Diese Schritte können daher sehr aufwendig sein und große Datenumfänge aufweisen, das Ergebnis ist jedoch meist ein eher überschaubarer Datensatz. Insbesondere in diesem Schritt ist daher Code Pushdown von Vorteil, weil Datentransporte und -kopien nicht anfallen und die in-memory Technologie von HANA enorme Geschwindigkeitsgewinne bietet. Doch auch die anschließende Modellbildung und Vorhersage gewinnt durch Code Pushdown an Effizienz. Da alle Verarbeitungsschritte in HANA selbst ablaufen, landen auch die Ergebnisse, also Modelle und Vorhersagen, in HANA und können von dort abgerufen werden. Im Optimalfall müssen also lediglich zur Anzeige in einem Report oder Dashboard Daten transportiert werden.
Technisch umgesetzt wird Code Pushdown für HANA, indem in Python lediglich Instruktionen erzeugt werden, die anschließend an HANA gesendet und dort ausgeführt werden. In Python erfolgt die Arbeit mit Repräsentationen der Daten statt mit den Daten selbst. Durch Python-Befehle wird so dynamisch ein komplexes SQL-Skript für HANA erzeugt und erst ausgeführt, wenn ein Ergebnis angefragt wird. So können aufeinanderfolgende Anweisungen aggregiert und optimiert werden.
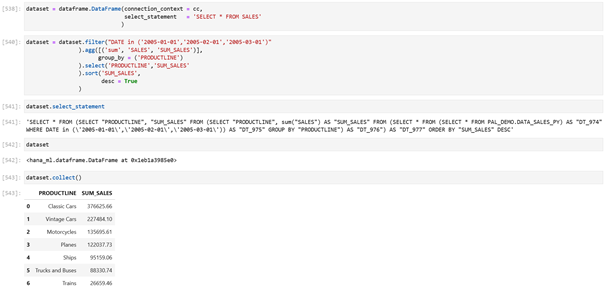
Abbildung: Daten aus der HANA-Tabelle SALES werden durch einen DataFrame in Python repräsentiert. Die Ausführung von Verarbeitungsschritten (Filter, Aggregation, Select, Sort) erfolgt per Code Pushdown in HANA selbst. Es werden erst dann Daten zum Python-Anwendungsserver übertragen, wenn dies explizit mit collect() angefordert wurden. Zuvor ist der Python-Datensatz lediglich eine virtuelle Repräsentation der angefragten HANA-Daten. Screenshot.
Im Idealfall wird die komplette Verarbeitung an eine HANA-Instanz gepusht. Bei sehr komplexen Aufgaben oder wenn der Einsatz spezieller Algorithmen gefordert wird, können die Möglichkeiten der PAL bzw. hana_ml durch Code Pushdown nicht mehr ausreichend sein. Hier kommt die Flexibilität und Erweiterbarkeit von Python als Universalprogrammiersprache ins Spiel. Dank der Kompatibilität der virtuellen HANA-Datensätze mit Pandas DataFrames, einem weit verbreiteten Python-Paket zur Datenverarbeitung, sind sehr einfach gemischte Datenpipelines umsetzbar. Eine spezielle Teilaufgabe der Pipeline wird in Python abgearbeitet, während vorhergehende und nachfolgende Schritte wieder nativ in HANA durchgeführt werden. Dadurch lässt sich der Transfer von Daten, und somit Zeit, Bandbreite und Kosten, ohne die jeweiligen Vorteile einer Python- bzw. HANA-Umgebung aufzugeben, reduzieren.
Beschreibt das Szenario bisher wie ein Data Scientist vorgeht, um sich mit Daten, Modellen und Vorhersagen vertraut zu machen, so ist das Ziel der produktive Einsatz der Analysenerkenntnisse. Meist erfolgt dazu die Implementierung einer (teil-)automatisierten Data Science-Pipeline und es bietet sich an, die erweiterten Möglichkeiten in Python gegenüber HANA-nativem SQL zu verwenden. Beispielsweise bringen hana_ml oder andere Python-Pakete getestete Lösungen zur Speicherung und Versionierung von Machine Learning-Modellen, zum Scheduling oder zum Bau von Pipelines bereits mit.
HANA als Graphendatenbank
Neben Machine Learning lassen sich noch weitere Funktionalitäten von einem Anwendungsserver in HANA auslagern. Das hana_ml Package integriert dazu weitere Funktionalitäten aus HANA, unter anderem Graphen. Die Vorteile von Graphendatenbanken können Sie im Blogbeitrag Einsatz von Graphendatenbanken für Produkt- und Prozessdaten im Manufacturing nachlesen. Zum Einstieg in die neue Welt der Graphendatenbanken bietet es sich an, bereits vorhandene Systeme mit einfachem Zugriff über hana_ml zu nutzen. Die eigentliche Arbeit wird dabei wieder per Code Pushdown in HANA selbst ausgeführt.
Nach dem Erstellen einer Verbindung zu HANA lässt sich aus den vorhandenen, klassischen Tabellen mit relationalen Beziehungen in nur einer Zeile Code ein Graph erstellen. Im untenstehenden Beispiel lassen sich so aus zwei Tabellen der internationalen Flughäfen und deren Flugverbindungen ein Graph der internationalen Flugbeziehungen erstellen.

Abbildung: Ausschnitt des Geflechts an Flugrouten zwischen internationalen Flughäfen. Wenn die Beziehungen zwischen Objekten vielfältig und von Interesse sind, wie bei Flügen oder Stücklisten, können Graphendatenbanken ihre Vorteile ausspielen. Eigene Darstellung.
Mithilfe dieses Graphen ist es nun ein Leichtes, die Beziehungen der Flughäfen untereinander zu analysieren. Genauso vereinfachen Graphen die Arbeit mit relationalen Tabellen, beispielsweise wenn es darum geht, die Abhängigkeiten zwischen Bauteilen und Baugruppen in einem Produkt zu verwalten.
Python in HANA
Die Python-Instanz, aus der der Code Pushdown zu HANA erfolgt, kann selbst in HANA ausgeführt werden. So lässt sich wie beim Einsatz von SQL-Skript und UI5 im Blogbeitrag "Predictive Analytics mit UI5" eine Lösung rein auf Basis eines HANA-Systems erreichen. Der XS Advanced (XSA) Applikationsserver bietet seit HANA 1.0 SPS12 die Möglichkeit Python Runtimes einzurichten. Dabei handelt es sich um isolierte Container, die einen Python-Applikationsserver bereitstellen und bspw. auch ein Dashboard ausliefern können. Je nach Einsatzszenario kann es zur Trennung der Systeme auch sinnvoll sein, die Python-Instanz unabhängig zu halten – entweder auf einer weiteren (virtuellen) Maschine oder in der Cloud. Dank des Code Pushdowns sind die Anforderungen an die Instanz gering, sodass auch kostengünstige Microservices wie AWS Lambda in Frage kommen.
Sie wollen mehr erfahren? Kontaktieren Sie uns für ein unverbindliches Beratungsgespräch!

Ähnliche Beiträge:

Wie realistisch ist Seamless Planning mit der SAP Analytics Cloud? Der Blogbeitrag zeigt, welche technischen Hürden aktuell bestehen, wie das Q4/2025 Release mit den neuen Live Versions neue Möglichkeiten eröffnet und welche Rolle SAP Datasphere und Databricks in einer zukunftsfähigen Planungsarchitektur spielen.

KI um der KI willen zu machen, führt selten zum gewünschten Ergebnis. Der Aufwand zur Umsetzung ist hoch, der tatsächliche Nutzen gering. Das Verhältnis zwischen Investition und Ergebnis stimmt nicht. Und genau das sorgt häufig für Frust in Teams und Führungsetagen. Der Schlüssel zu erfolgreicher KI liegt nicht in noch komplexeren Modellen, sondern in der Auswahl der richtigen Use Cases. Und wie man genau diese erkennt, zeigen wir in diesem Beitrag.

Die Business Data Cloud (BDC) wurde offiziell vorgestellt und markiert eine bedeutende Veränderung in der Art und Weise, wie Unternehmen ihre SAP-Daten verwalten, analysieren und mit externen Quellen verknüpfen. Doch was bedeutet das für Unternehmen, die heute auf SAP BW oder Datasphere setzen? Welche Rolle spielt Databricks? Und wie verändert sich die SAP-Datenstrategie durch diese neue Plattform?
