
Nicht immer ist die Einführung neuer Analysesysteme notwendig der sinnvoll um Data Science, oder tiefgehende Auswertung aller verfügbaren Unternehmensdaten durchzuführen. Ist bereits eine SAP HANA-Datenbank vorhanden, so kann zusätzlicher Aufwand an Infrastruktur und neues Personal möglicherweise vermieden werden. Denn in SAP HANA ist technisch bereits alles nötige vorhanden, um mit Machine Learning und Advanced Analytics neue wichtige Erkenntnisse über Ihr Unternehmen zu gewinnen.
Anbieter und Möglichkeiten
Um mit wissenschaftlichen, vor allem mathematischen Methoden, Wissen und Erkenntnisse aus strukturierten und unstrukturierten Daten zu gewinnen ist eine technische Umgebung mit passender Hardware und Software nötig. Mithilfe von Machine Learning (ML) und künstliche Intelligenz (KI) lässt sich der große Datenschatz heutiger Unternehmen systematisch nutzen. Vorhersagen auf Basis vorhandener Daten ermöglichen beispielsweise den verbesserten Einsatz von Ressourcen, optimierte Planung oder die Automatisierung manueller Aufgaben. Die großen Cloud Provider (Amazon, Microsoft, Google) decken mit ihren Produkten diese Anforderungen mühelos ab.
SAP selbst bietet mit der SAP Analytics Cloud (SAC) und SAP Data Intelligence ebenfalls Machine Learning bzw. Data Science-Lösungen an. Die SAC wird bereits häufig von unseren Kunden als zentrales Frontend für Reporting und Planning eingesetzt. Smart Predict in der SAC bietet darüber hinaus einen einfachen Zugang zu KI, stellt sich jedoch leider als Blackbox dar. Anpassungen der Algorithmen sind nicht vorgesehen. Data Intelligence bietet zwar eine komplette Data Science-Umgebung, ist jedoch für typische Anforderungen unserer Kunden unnötig groß und komplex, was sich dementsprechend auch in den Kosten niederschlägt. Eine spannende Alternative ist Data Science mit Hilfe der in HANA integrierten Möglichkeiten.
SAP HANA
Ein für Data. Science, Machine Learning und KI ausreichend starkes System ist bei den meisten unserer Kunden typischerweise bereits lokal im Einsatz. Dabei kann es sich bspw. um ein S/4HANA oder BW on HANA, oder BW/4HANA handeln. Damit ist alles technisch notwendiges bereits im Haus. So verfügt die HANA Datenbank bspw. bereits über eine mächtige Machine Learning-Bibliothek: die Predictive Analytics Library (PAL).
Predictive Analytics Library (PAL)
Bei der PAL handelt es sich um eine Application Function Library (AFL), um den Funktionsumfang der HANA-Datenbank zu erweitern. Etwa 180 Funktionen aus den Bereichen Statistik, Machine Learning, künstliche Intelligenz und Datenverarbeitung sind derzeit integriert. Unter anderem decken diese die Gebiete Clustering und Klassifikation über Regression und Zeitreihen bis hin zu Vorschlagssystemen ab. Die Bedienung der Funktionen erfolgt in HANAs nativer Sprache, SQL Script, mithilfe von Stored Procedures und Tabellen.
Durch die Integration in HANA ergeben sich einige handfeste Vorteile gegenüber anderen Machine Learning -Bibliotheken: Funktionen werden in der Datenbank und damit direkt an den Daten ausgeführt. Langsames Kopieren auf einen Anwendungsserver entfällt und Daten müssen nicht doppelt vorgehalten werden. Durch HANAs in-memory-Technologie ergeben sich weitere Geschwindigkeitsvorteile.
Beispiel: Umsatzvorhersage in HANA
Ein einfaches Beispiel zeigt die Möglichkeiten der PAL und Data Science in HANA auf. Das Ziel ist die Vorhersage des Umsatzes mit verschiedenen Produkten über die nächsten 12 Monate. Die historischen Verkaufszahlen mit Umsätzen und weiteren Daten sind für das Reporting bereits in einem BW/4HANA vorhanden.
In HANA Studio/Eclipse ergibt sich folgendes Bild der letzten 29 Monate:
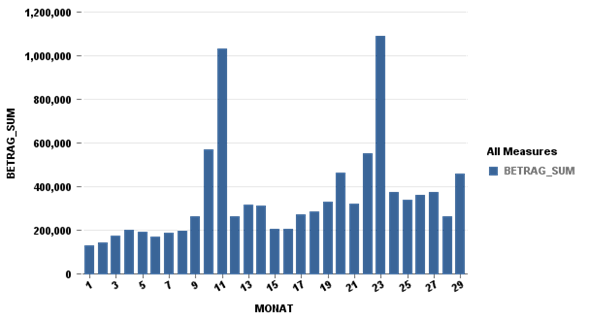
Eigene Darstellung
Eine starke saisonale Schwankung ist offensichtlich und es scheint auch ein steigender Trend vorzuliegen. Mithilfe der PAL-Funktionen SEASONALITY_TEST bzw. TREND_TEST lassen sich diese Beobachtungen testen und quantifizieren.
SEASONALITY_TEST erkennt eine 12-monatige Saisonalität mit einem starken Autokorrelationskoeffizienten von 0.466. Außerdem ergibt der Test, dass die saisonale Schwankung zusätzlich (additiv) zum Absatz über das Jahr hinweg auftritt. Der zusätzliche Bedarf in den umsatzstarken Monaten ist daher unabhängig vom Trend und den zufälligen Schwankungen.
Im TREND_TEST zeigt sich, dass in der Tat ein positiver Trend vorliegt. Mit einem p-Wert von 0.00156 zeigt der Test außerdem, dass es statistisch unwahrscheinlich ist, dass nur der Anschein eines Trends vorliegt.
Ausgehend von diesen Erkenntnissen soll für die Vorhersage nun ein ARIMA-Modell zur Anwendung kommen, dass Saisonalität und Trend abbilden kann. Je nach Ziel kann es jedoch auch sinnvoll sein, saisonale Komponenten und Trends getrennt zu betrachten. Mithilfe der PAL-Funktion AUTOARIMA können einige Parameter des Vorhersagemodells automatisch bestimmt werden, was für dieses einfache Beispiel Arbeit spart.
Nach Erstellen des Modells lässt sich die Qualität durch den Vergleich des Fits und der realen Daten erkennen. Für einen ersten Test ist das Modell gut genug, aber im praktischen Einsatz sollten mehr Daten hinzugezogen werden, um das Modell zu verbessern.
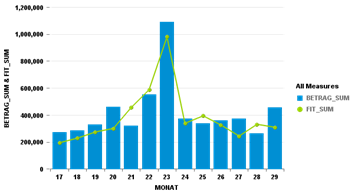
Eigene Darstellung
Mithilfe einer zweiten Funktion, AUTOARIMA_PREDICT, kann nun der Forecast über die nächsten 12 Monate erstellt werden. Neben der eigentlichen Vorhersage sind die Konfidenzintervalle und Fehlerbereiche wichtig, da sie die Unsicherheit des Forecasts angeben.
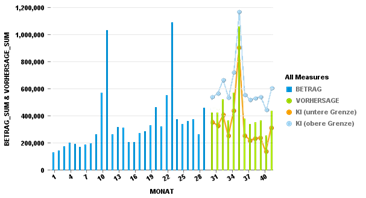
Eigene Darstellung
Das Beispiel demonstriert zwei wesentliche Schritte in Data Science Anwendungen: das Untersuchen der vorliegenden Daten und darauf basierend die Vorhersage und Analyse. Mithilfe der PAL lässt sich der komplette Data Science Workflow nativ in HANA ausführen, ohne externe Umgebungen bemühen zu müssen.
Die PAL außerhalb HANA nutzbar machen
So vielfältig die Möglichkeiten der PAL-Algorithmen auch sind, die Ausführung über SQL Script erfordert entsprechende Kenntnisse und Berechtigungen im System. Dank weiterer nativer Möglichkeiten in HANA lässt sich diese Schwierigkeit jedoch umgehen, und gleichzeitig der Einsatzbereich stark erweitern. Der HANA-Applikationsserver XS Classic bzw. XS Advanced (ab HANA 1.0 SPS 12 und HANA 2.0) ermöglicht den Einsatz der PAL aus der SAC und weiteren Anwendungen. Beispielsweise lässt sich so eine komplette Predictive Analytics Pipeline als interaktive Anwendung in der SAC implementieren.
Sie wollen sich direkt mit uns über die Möglichkeiten von Data Science in HANA informieren? Dann kontaktieren Sie uns gerne unverbindlich!

Ähnliche Beiträge:

Wie realistisch ist Seamless Planning mit der SAP Analytics Cloud? Der Blogbeitrag zeigt, welche technischen Hürden aktuell bestehen, wie das Q4/2025 Release mit den neuen Live Versions neue Möglichkeiten eröffnet und welche Rolle SAP Datasphere und Databricks in einer zukunftsfähigen Planungsarchitektur spielen.

KI um der KI willen zu machen, führt selten zum gewünschten Ergebnis. Der Aufwand zur Umsetzung ist hoch, der tatsächliche Nutzen gering. Das Verhältnis zwischen Investition und Ergebnis stimmt nicht. Und genau das sorgt häufig für Frust in Teams und Führungsetagen. Der Schlüssel zu erfolgreicher KI liegt nicht in noch komplexeren Modellen, sondern in der Auswahl der richtigen Use Cases. Und wie man genau diese erkennt, zeigen wir in diesem Beitrag.

Die Business Data Cloud (BDC) wurde offiziell vorgestellt und markiert eine bedeutende Veränderung in der Art und Weise, wie Unternehmen ihre SAP-Daten verwalten, analysieren und mit externen Quellen verknüpfen. Doch was bedeutet das für Unternehmen, die heute auf SAP BW oder Datasphere setzen? Welche Rolle spielt Databricks? Und wie verändert sich die SAP-Datenstrategie durch diese neue Plattform?
