
Das traditionelle Data Warehouse ist stark optimiert auf seinen Einsatzzweck als Analyticsplattform für BI und Reporting. Das macht es zwar schnell, sicher und konsistent, aber auch unflexibel. Anpassungen sind in Data Warehouses meist mit hohem Aufwand verbunden oder manchmal gar nicht möglich. Ihr jahrzehntelanger Einsatz beweist jedoch seinen Erfolg.
Data Lakes dagegen sind sehr flexibel bezüglich Dateninhalten, Verarbeitung und Anwendung, jedoch auch inkonsistent und schwer überschaubar. Im Laufe der Zeit verkommen sie daher oft zu Data Swamps (Datensümpfen) – undurchdringliche Ansammlungen Daten aller Art. Aufgrund ihrer Flexibilität und der Fähigkeit, einfach mit sehr großen Datenmengen umgehen zu können, sind Data Lakes aus der heutigen Datenlandschaft nicht mehr wegzudenken.
Wie kann man nun das Beste aus beiden Welten in einer Datenplattform vereinen?
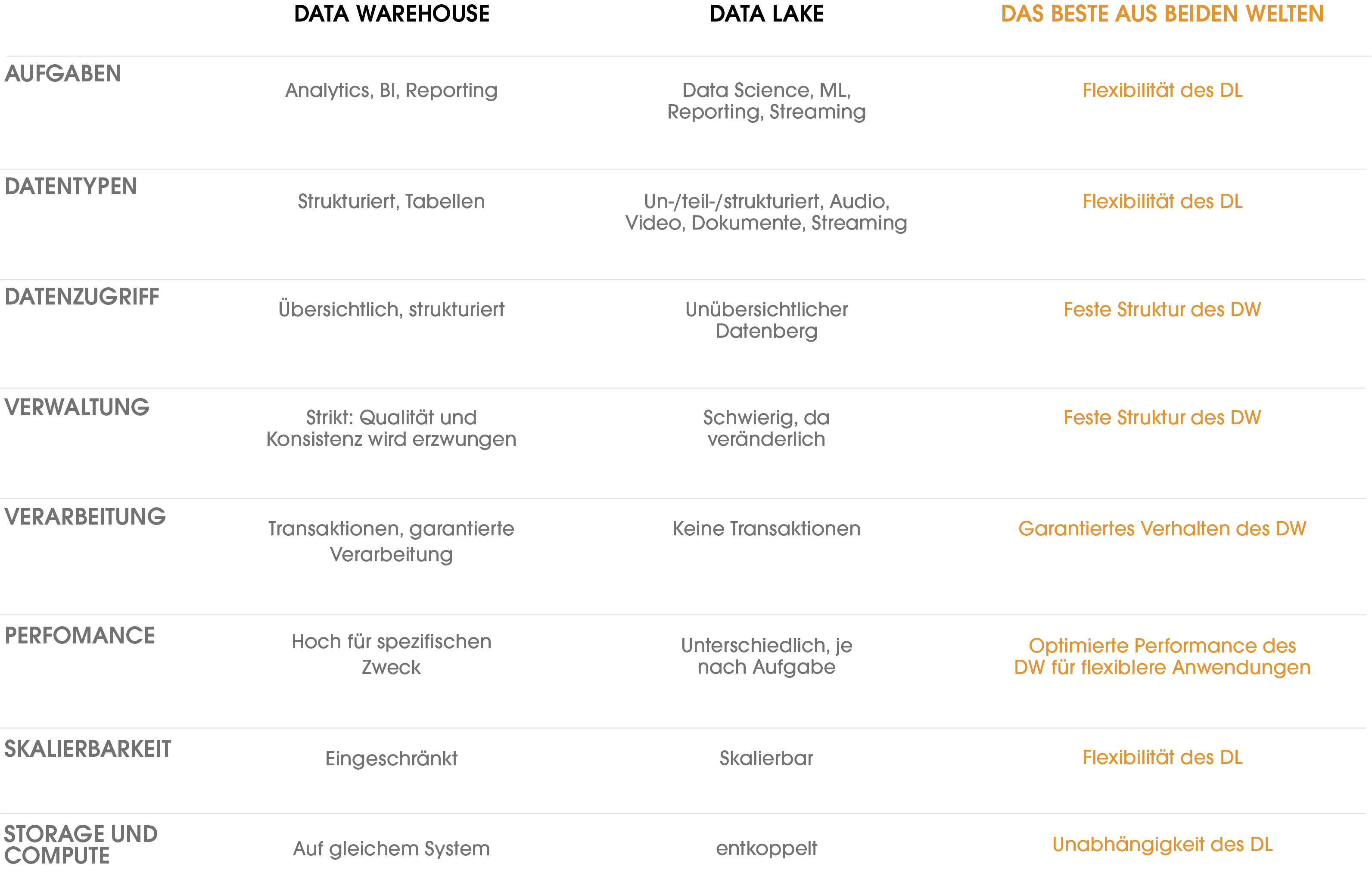
Diese Eigenschaften von Warehouses und Data Lakes listet die oben stehende Tabelle. Im Idealfall sollte eine Datenplattform alle Vorteile bieten, ohne die Nachteile zu übernehmen. Diesem Ideal nähert sich die Lakehouse-Architektur an: Sie nutzt ähnliche Datenstrukturen und Managementansätze wie Data Warehouses, baut aber auf günstigem Objektspeicher für Cloud Data Lakes auf. Ein Lakehouse enthält eine Managementschicht, die den Speicher verwaltet und Governance-Funktionen bereitstellt. Das Schaubild eines Lakehouses zeigt außerdem, dass der Datenzugriff für alle Anwendungen über die Managementschicht geführt wird. Anwender haben komfortabel Zugriff und müssen sich nicht mit Details der Datenspeicherung befassen.
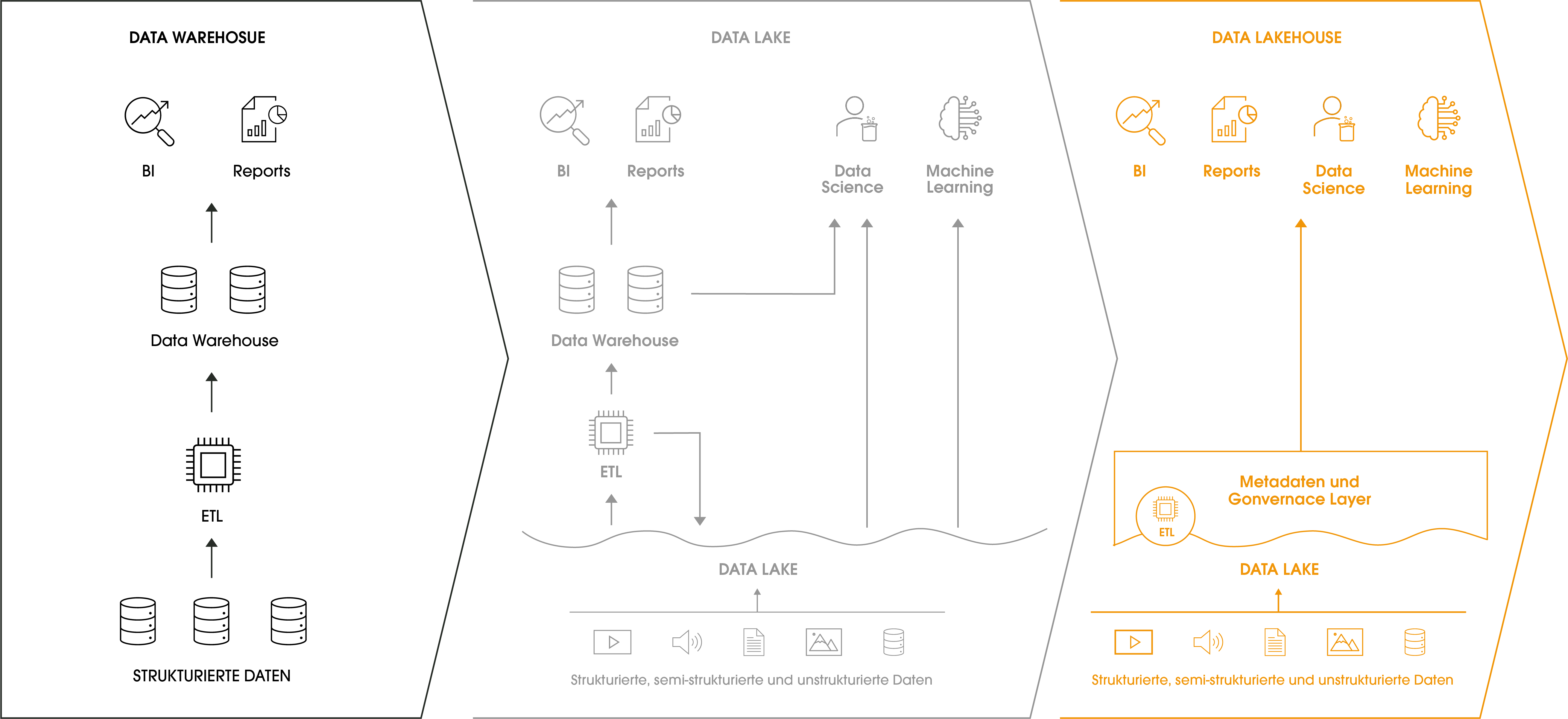
Datenspeicherung im Lakehouse
Auf Datenebene kommt für das Lakehouse beispielsweise AWS Simple Storage Service (S3) oder Azure Blob Storage zum Einsatz. So können beliebige Daten und Dokumente auch in großen Mengen kostengünstig gespeichert werden. Diese Grundlage ermöglicht es, wie in Data Lakes, flexibel auf Veränderungen der Geschäftsprozesse einzugehen und neue Daten einfach in bestehende Prozesse aufzunehmen. Die technische Grundlage bildet ein quelloffenes Dateiformat, wodurch ein Vendor Lock-in vermieden wird.
Datenmanagement im Lakehouse
Das Management der Daten orientiert sich in einem Lakehouse an den bewährten Strukturen der Data Warehouses. Die Erhaltung der Konsistenz der Daten ist im operativen Einsatz von grundlegender Bedeutung, wofür Transaktionen die technische Grundlage sind. Das Datenmanagement im Lakehouse ermöglicht Transaktionen mit garantiertem Verhalten, indem analog zu einem Warehouse ein Transaktionslog geführt wird und bei Fehlern Rollbacks durchgeführt werden. Durch diese Verarbeitungsweise ergeben sich außerdem Möglichkeiten zur Performanceoptimierung gegenüber Data Lakes.

Transaktionen ermöglichen garantiertes Verhalten von Datenoperationen auf Grundlage der vier Prinzipien Abgeschlossenheit, Konsistenz, Isolation und Dauerhaftigkeit.
Des Weiteren speichert das Lakehouse zu jedem Datensatz umfangreiche Metadaten, die unter anderem Kommentare, Zeitstempel, Versionierung und Versionsverläufe ermöglichen. Damit lassen sich beispielsweise Audits oder Rollback durchführen, beides Möglichkeiten, die man in Data Lakes leider oft vergebens sucht.
Das Datenmanagement eines Lakehouses erlaubt es außerdem, komplexe Berechtigungssysteme abzubilden – ebenfalls von wesentlicher Bedeutung im operativen Einsatz. Während Data Lakes nur Berechtigungen auf Dateiebene unterstützen, also Zugriff oder Verweigerung ganzer Tabellen, sind im Lakehouse auch Berechtigungen auf Inhalte möglich, zum Beispiel Tabellenspalten oder -zeilen.
Bessere Performance und Skalierung durch Entkopplung von Speicher und Rechenleistung
Eines der Prinzipien der Lakehouse-Architektur ist die Trennung von Speicher und Rechenleistung. Dieser Ansatz vermeidet die typischen Warehouse-Probleme von vorausschauender Dimensionierung und Ressourcennutzung. Der Cloudspeicher des Lakehouse skaliert praktisch unbegrenzt und vollkommen unabhängig von der benötigten Rechenleistung. Auf Basis von Apache Spark für schnelle, parallele Datenverarbeitung kann Rechenleistung passend zum Einsatzzweck bereitgestellt werden: Der tägliche ETL-Job läuft damit kostenoptimiert, während der zeitkritische Streaming-Job von einer latenzoptimierten Maschine übernommen wird. Je nach Bedarf skaliert die Rechenleistung so nahezu unbegrenzt.
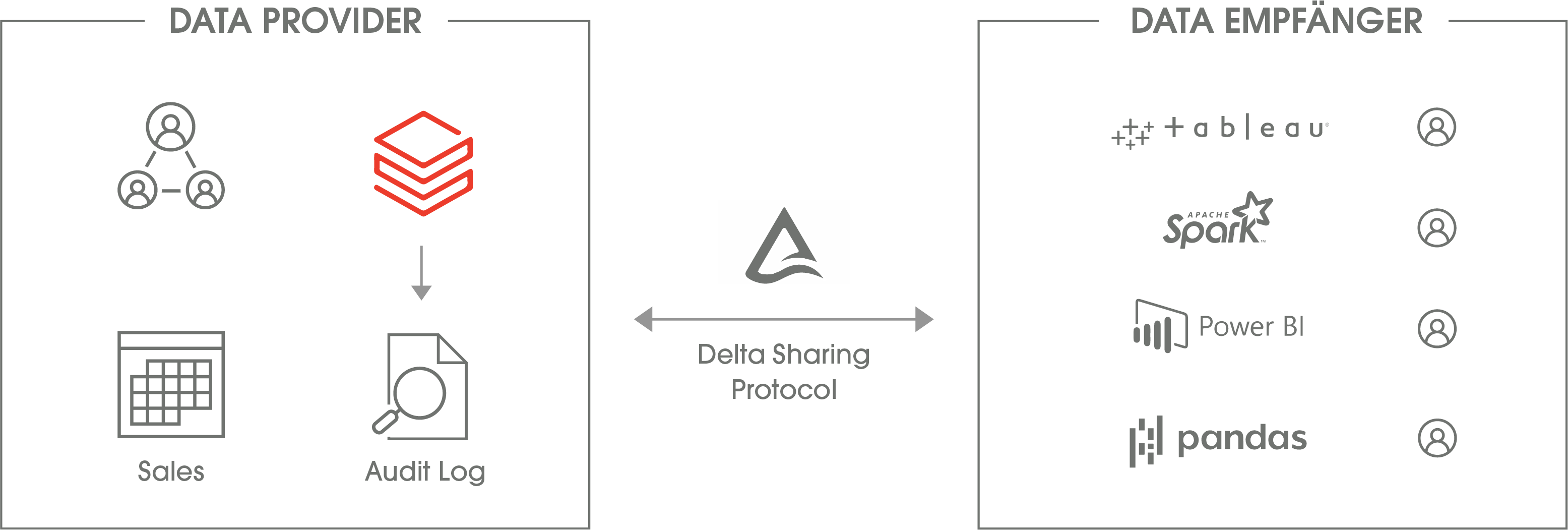
Datenfreigaben ermöglichen einfachere Zusammenarbeit zwischen Personen, Abteilungen oder Programmen hinweg.
Daten zugänglich machen
Der beste Ansatz zur Speicherung und Verarbeitung nützt nichts, wenn die Daten nicht bei den Personen ankommen, die sie benötigen. Daher sind Datenkatalog und Datenfreigabe ein weiterer zentraler Punkt des Lakehouse. Der Datenkatalog ermöglicht das Auffinden von Daten an zentraler Stelle und reduziert damit Aufwand und Zeit, bis neue Erkenntnisse aus den Daten gewonnen werden.
Das Lakehouse im Einsatz
In der Praxis ermöglicht ein Lakehouse die Vereinfachung der Datenplattform durch eine gemeinsame Plattform mit den Vorteilen von Data Warehouse und Data Lake statt des parallelen Betriebs beider Systeme. So werden abgeschottete Datensilos vermieden und die Trennung zwischen den Aufgabenfeldern Analytics, deren Anforderungen das Warehouse abdeckt, und Data Science, wo eher Data Lakes zum Einsatz kommen, reduziert. Ein Lakehouse fördert also die Zusammenarbeit auf einer gemeinsamen Datenbasis, um neue Werte aus Daten entstehen zu lassen.
![]()
Lakehouse as a Service: Databricks
Lakehouse ist eine Open Source-Architektur, die sich mit verschiedenen Tools und Services umsetzen lässt. Databricks ist der Marktführer für Lakehouse-Implementierungen und bietet als Cloud-Service eine Lakehouse-Plattform unter dem Namen „Delta Lake“ an. Die Grundlage bildet dabei die Cloud des Kunden (Amazon Web Services, Microsoft Azure, Google Cloud Plattform), ergänzt durch die Datenmanagement-Funktionen des Lakehouse, die durch Databricks bereitgestellt werden. Darüber hinaus bietet Databricks eine umfangreiche Umgebung für Data Science und Analytics.
Wie kann ein Lakehouse Ihr Unternehmen weiterbringen?
Wie die meisten neuen Architekturen bietet das Lakehouse vielfältige Möglichkeiten. Wo die größten Chancen und Vorteile liegen, ist jedoch von der individuellen Situation abhängig. Kontaktieren Sie uns für ein unverbindliches Gespräch, um Ihr Potenzial durch eine verbesserte Datenarchitektur auszuschöpfen.

Ähnliche Beiträge:

Wie realistisch ist Seamless Planning mit der SAP Analytics Cloud? Der Blogbeitrag zeigt, welche technischen Hürden aktuell bestehen, wie das Q4/2025 Release mit den neuen Live Versions neue Möglichkeiten eröffnet und welche Rolle SAP Datasphere und Databricks in einer zukunftsfähigen Planungsarchitektur spielen.

Die Business Data Cloud (BDC) wurde offiziell vorgestellt und markiert eine bedeutende Veränderung in der Art und Weise, wie Unternehmen ihre SAP-Daten verwalten, analysieren und mit externen Quellen verknüpfen. Doch was bedeutet das für Unternehmen, die heute auf SAP BW oder Datasphere setzen? Welche Rolle spielt Databricks? Und wie verändert sich die SAP-Datenstrategie durch diese neue Plattform?

